
Metis - Project Luther
An Application of Linear Regression on Webscraped Movie Data
High-Return Low-Budget Films: What makes them so special? (and profitable)
Introduction
Using Linear Regression and variable selection techniques, I will investigate the association between highly successful low-budget films and a set of variables that may explain their success. The data for this model is scraped from several movie review websites.
Motivation
We could look at the financial success of all movies and build a model accordingly. However, due to resource constraints, we will restrict this study to low-budget films. A film’s success will be measured by its return on investment or ROI. Given this, we wish to build a model that associates ROI with the characteristics of a movie.
Definitions
We will define “low-budget” as movies with budgets under $2M U.S. dollars.
We will define Return on Investment (ROI) as: (Revenue – Budget) / Budget
Data
Since we strive to find associations between ROI and a movie’s characteristics, possible characteristics or features to include in our model are:
- Critic Scores
- Runtime
- Widest Release
- Genre
- MPAA Rating
- Distributor
To gather this data, the following sites were scraped using BeautifulSoup in Python:
- Revenue and Budgets: The-Numbers.com
- Critic Scores: RottenTomatoes.com
- Others: BoxOfficeMojo.com
~300 data points were gathered to train the regression model.
Analysis
Based on the above features, let’s construct a preliminary linear regression model:
ROI = Critic Scores + Runtime + Widest Release + Genre + MPAA Rating + Distributor
As we will see in our results, not all of these variables are meaningful and are subsequently dropped from the model by variable selection techniques. For example, there is absolutely no correlation between Runtime and ROI, as expected, and thus the variable should not be included in the final model.
Results
Using Stepwise variable selection, the following features remain in the model:
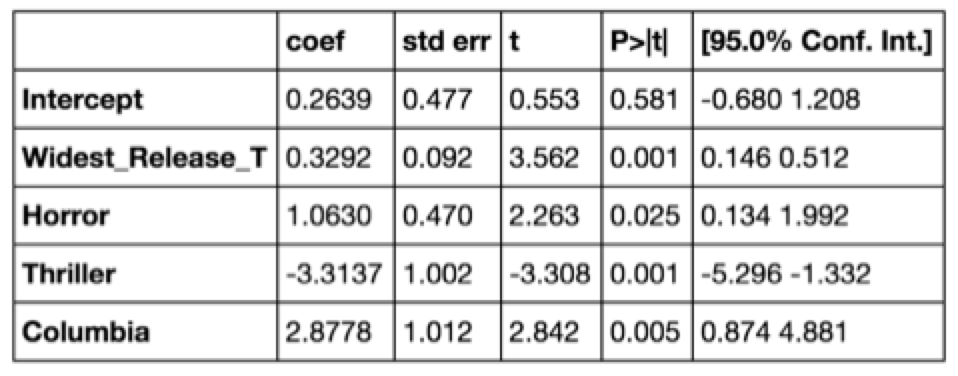
ROI = Widest Release + Horror + Thriller + Columbia
Horror and Thriller are variables derived from the Genre category and Columbia from the Distributor category.
This model achieved an Adjusted R^2 of 0.31. All variables in the model are statistically significant at a significance level of 0.03.
Visually, here are the relationships between ROI and the variables in the model:
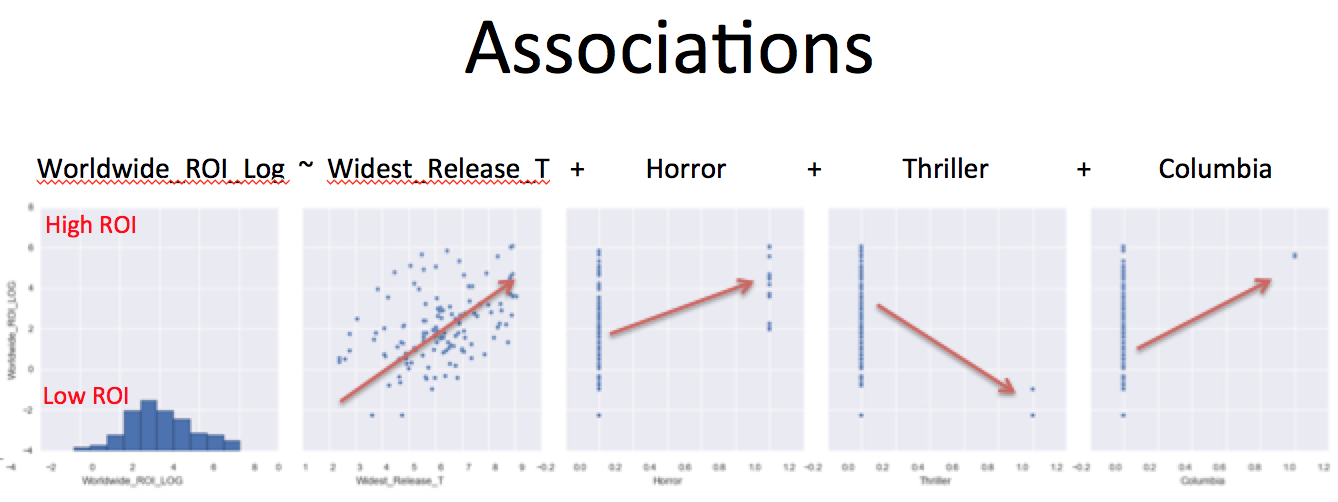
As the ROI increases, there is a strong positive correlation with the size of the widest release for a movie. Similarly, Horror movies tend to be correlated with a greater ROI. Although not too many data points exist, the two thriller movies in the model were associated with relatively low ROIs, thus their negative contribution in the model. In contrast, the two movies that were distributed by Columbia performed very well and thus the Columbia indicator contributes to the model positively.
Model Summary Statistics:
Summary
In summary, should we invest based on this model? No.
But if you really want to, aim at making a Horror film without any Thrill, that is distributed by Columbia with the widest release possible in order to maximize your ROI.
In the meantime, let’s dig for more data (features) or we re-evaluate how we approach this particular question to arrive at a better model.
Additional Thoughts
Stepwise Variable Selection was used to eliminate insignificant variables and optimize our Adjusted R^2.
Running a CVLasso (SciKit Learn) on this Model yields a lambda = 0.001, indicating that the model warrants no additional cross validation penalties.
Here is a link to view the presentation given at Metis: PDF of Presentation